

Il mese scorso ci siamo imbattuti in un articolo che al di là della tecnica tocca interessanti tematiche.
Non si parte con la più descrittiva delle immagini a dire il vero ma, approfondendo solo un poco emerge subito qualcosa di utile.
Dove stanno andando i dati, qual è il trend del mondo dell’archiviazione?
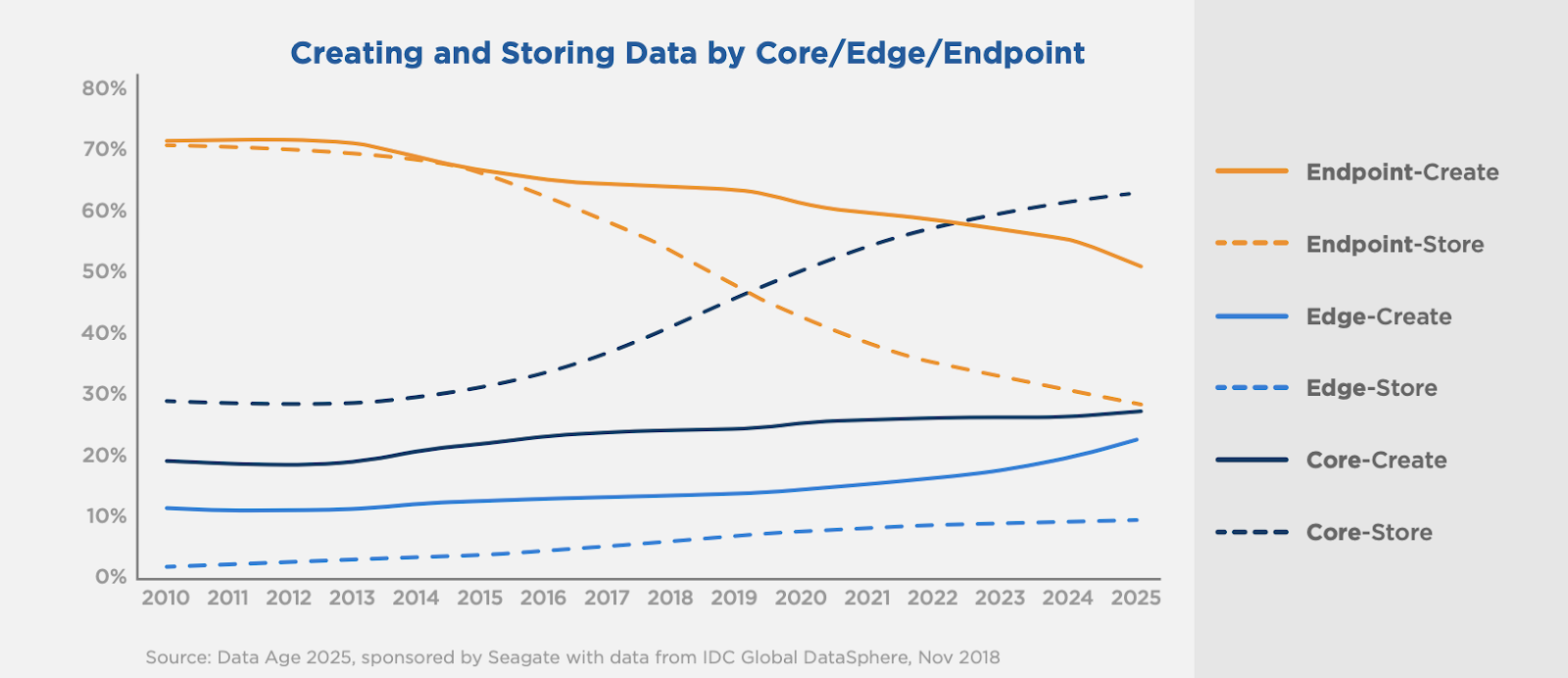
La linea blu tratteggiata ci risponde in modo molto chiaro, il mondo dello storage si sta spostando sempre più da archivi delocalizzati - Endpoint - a grandi archivi centralizzati - Core.
Qui la fonte:
https://ceph.io/community/diving-into-the-deep/
Non è detto che siano solo su cloud pubblici, potrebbero essere anche on premise, quindi datacenter realizzati “in casa”.
Quindi grandi spazi dedicati allo storage e ci riferiamo sia a data lake (per semplificare: grossi archivi di dati grezzi) che a data warehouse (grossi archivi di dati più filtrati e strutturati).
Un link ad un articolo che ne elenca le principali differenze qui:
https://www.talend.com/it/resources/data-lake-vs-data-warehouse/
Un altro trend interessante in evidenza è dove vengono generati i dati, molto semplicemente nello stesso posto, sempre nel core, e nelle organizzazioni private ed aziendali.
“..Dove ci sono dati, ci sarà anche potenza di calcolo per estrarre informazioni. Nel core ci sono grandi volumi di dati ed è lì che questi dati vengono anche aggregati, filtrati, indicizzati e catalogati..”
E da qui emerge un altro dato di rilievo:
“Il disaccoppiamento di elaborazione e archiviazione è già comune nei core, sia quando parliamo di cluster di storage locali che di quelli ospitati in un cloud pubblico. La tendenza verso elaborazione e archiviazione disaccoppiati dovrebbe accelerare con la proliferazione di hardware di elaborazione specializzato come GPU, FPGA e TPU. In un'architettura dati disaccoppiata, i dati sono prevalentemente persistenti in sistemi o servizi di storage di oggetti dedicati.”
Quello che si intende raccontare è la scelta che viene operata dagli addetti ai lavori e dagli ingegneri di separare i cluster dedicati allo storage da quelli dedicati al calcolo.
L’iperconvergenza per esempio, tecnologia interessante da molti punti di vista, in primis quello della condivisione di risorse, che porta a notevoli economie di scala, non è più adeguata nell’ambito dei Big Data e delle successive elaborazioni cui sono sottoposti questi dati grezzi.
Si pensi al machine learning, all'intelligenza artificiale ecc.
Quindi quale può essere la scelta architetturale che permetta di soddisfare sia i necessari requisiti di flessibilità ed espandibilità che quelli di integrazione con sistemi di calcolo già esistenti, mantenendo anche i piedi saldi a terra dal punto di vista dell’affidabilità e degli economics, voce di progetto quest’ultima non trascurabile?
“..In un'intervista del 2018 riguardante l'archiviazione di oggetti per i big data, Mike Olson, ex CTO di Cloudera, ha usato il termine "luci spente" per descrivere le persone che lavoravano su Ceph. Oggi, ci sono organizzazioni e iniziative come Massachusetts Open Cloud che sfruttano lo storage di oggetti Ceph nel core, fungendo sia da data lake che come parte di un data warehouse disaccoppiato..”
E qui si giunge al nocciolo della questione, come rendere economica una soluzione simile?
Ceph è nato per aggregare risorse, dischi di diversa natura in pool gestiti in modo differente, quindi non solo ssd o nvme quando il dato non lo richiede, ma anche rotativi di grandi dimensioni.
Si sposta il focus dall’esigenza di prestazione e di sicurezza, dalla caratteristica hardware spinta al numero di elementi hardware presenti.
Con Ceph in pratica più nodi ci sono meglio è, da lì derivano prestazioni e affidabilità superiori.
Quindi è possibile spingersi fino a valutare l’utilizzo di server refurbished in taluni casi e sicuramente il fatto che sia un prodotto open source senza necessità di licenze da applicare a seconda delle macchine sulle quali il software va ad operare lo rende ancora più interessante.
Cosa si può fare lo abbiamo raccontato in articoli precedenti citando illustri utilizzatori di Ceph ma anche dal link citato all’inizio di questo contributo si può estrapolare quanto segue:
“..L’archiviazione delle funzionalità offline può spingere molti sistemi di archiviazione al limite e per assicurarci che sia all'altezza del compito, abbiamo superato i limiti di Ceph (throughput aggregato raggiunto in lettura: 79.6 GiB/s). Nel febbraio del 2020, abbiamo caricato un cluster Ceph a 7 nodi con 1 miliardo di oggetti e , a settembre, avevamo ridimensionato i nostri sforzi di test per archiviare 10 miliardi di oggetti in un cluster Ceph a 6 nodi. Ceph utilizza il posizionamento algoritmico, quindi il numero di oggetti che il cluster è in grado di memorizzare è relativo al numero di nodi. Scalando fino a centinaia di nodi e utilizzando formati come Parquet e TFRecord, Ceph è in grado di proteggere e fornire un accesso ad alta velocità a trilioni di oggetti e funzionalità..”
Dunque per concludere la scelta di questa tecnologia può essere decisiva per chi ha la necessità di realizzare un cluster di storage dedicati alla gestione di grandi quantità di dati, ma sorprendentemente anche richieste più modeste, a partire da un numero minimo di 4 nodi, sono ormai perfettamente in linea con architetture Ceph (anche in configurazione di iperconvergenza), che è dunque diventato “una soluzione hi-tech” da tenere in grande considerazione per quasi ogni esigenza.
Enterprise OSS Staff
